當把服務部署至 k8s cluster 並上線正式對外後,Day 2 operation 便成了維運的重點。要如何將散落在各 pod 上的 log 集中管理,並有方便的 UI 可以查詢,同時搭配視覺化工具與程式語言,可以用來做為關鍵指標統計與監控,對 SRE 而言,便成了至關重要的課題了。
本文將介紹用來做為 log 收容集中,並且也可以收集效能 metrics 的 Loki stack 最基本的安裝與設定
市面上用來做為收集 log 的 logging system 有蠻多樣的,其中比較有名的像是 EFK / ELK 或者是 Graylog,這些背後都有使用到 Elasticsearch 做為 log 儲存使用。雖然這類的方案功能豐富也強大,但往往所需要的資源也更多,且設定複雜(後續維護上,所需要的技術門檻以及學習曲線也就越高了)。如果環境不複雜,其實用 Loki 就已經足夠使用。
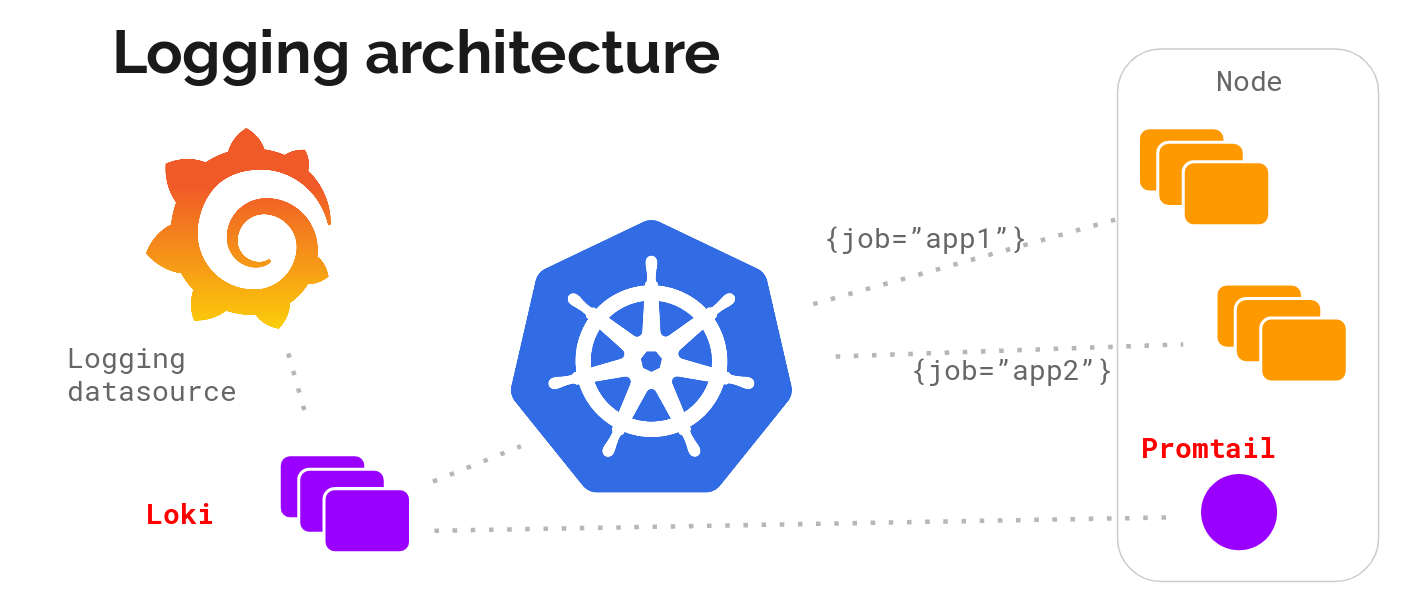
Loki 是受到 Prometheus 所啟發,具有水平可擴展、高可用性、多租戶日誌聚合系統,使用上真的跟 Prometheus 的味道有一點像。相較於其他的 logging system,Loki 的架構非常的簡單,也跟 Prometheus 一樣,用 label 來作為 index。
在 Loki stack 裡,可以搭配 promtail(最常用)、fluent-bit、filebeat、logstash,將設定的目錄之下裡頭的 log,轉送至 loki 集中儲存。
除了將 log 集中 logging 的功能,loki-stack 也包含了 prometheus(以及 node exporter) / grafana 這兩個服務,讓 prometheus 可以透過 k8s service discovery 的功能,自行去發現 node, pod, service, endpoint …. 等,當 k8s cluster 狀況有變更時,prometheus 會自己根據異動(如新增 worker node、pod 增減 …. etc),自行去各個設定的 target 收集 metrics,而不需要人工的介入更改 prometheus 設定。
目前有一些商業版的 k8s cluster 軟體,例如 Red Hat 的 OCP,就有將 prometheus 做為其 k8s cluster solution 內監控效能的元件。
**註:
Prometheus 陣營也有類似的 solution,也就是 prometheus-stack,差別只在於 loki-stack 多了收 log 的套件(就是 loki, promtail, ,其他部份差不多,也都可以使用 helm chart 來安裝。**